| | 
|
Service Continuity Management
Table of Contents
|
|
|
The increased dependency on IT by the 'business' and external customers has necessitated in establishing IT Contingency Planning. This will not only maintain and preserve services it will contribute to the very survival and continuance of an organization. Statistics indicate an extremely high number of businesses fail within a year of a major disaster. There is also the consideration that planning to contain Service failures protects the Profit or Loss of the company, and assists in the retention of customer confidence and credibility.
This process needs to be re-written for confomance with ITIL Version 3. By the way, does anyone, other than me, wonder why this isn't covered under Availability Management? I suggest it's a difference in degree and not in kind and that many of the processes are related - Continuity processes are just the most severe result of Unavailability.
More...
|
|

|
Introduction to Service Continuity Management
Service Continuity Management is a process within the Service Design module of the ITIL Service Lilfecycle.
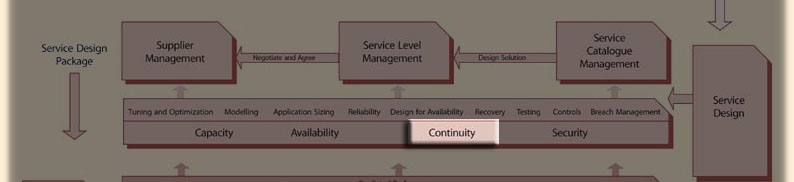
IT Service Continuity Management (ITSCM) has two major facets which have direct parallels to process activities found in Incident Management:
- the magnitude of the outage. The emphasis in Incident Management is the restoration of normal (ie., pre-outage) service. The goal is primarily to restore that service as soon as possible. A secondary goal is to contain and minimize the business effects of the outage. Likewise, ITSCM seeks to restore full service as quickly as possible. The processes designed to do this are referred to as "Disaster Recovery". The services designed to contain and minimize the overall affects of the outage are called "Business Continuity Planning".
- Incident Management covers a wide latitude of systems and hardware comprising the infrastructure. These Configuration Items (CIs) have designations which distinguish them on the basis of overall importance to business operations within the enterprise. Within the Incident Management system, this importance is reflected in Priority and Urgency definitions which are attached and govern the restoration effort.
ITSCM considers those IT assets and configurations that support survival critical business processes. The installation of mechanisms to deliver ITSCM may not necessarily be sufficient to keep those business processes operating after a service disruption. Should it be necessary to relocate to an alternative working location, provision will also be required for items such as office and personnel accommodation, copies of critical paper records, courier services and telephone facilities to communicate with Customers and third parties.
![[To top of Page]](../images/up.gif)
Service Continuity Management
The primary objective of business continuity planning is to protect the organization in the event that all or parts of its operations are rendered unusable. The planning process should minimize the disruption of operations and ensure some level of organizational stability and an orderly recovery after a disaster. This is accomplished by:
- Ensuring the safety of customers, employees and other personnel during and following a disaster
- Minimize the costs associated with disaster potentials that cannot be eliminated
- Enhancing the sense of security
- Minimizing risk of delays
- Guaranteeing the reliability of standby systems
- Providing a standard for testing the Disaster Recovery Plan (DRP)
- Minimizing decision-making during a disaster
Critical Success Factors
- A no-break power system is installed and regularly tested
- Potential availability risks are proactively detected and addressed
- Critical infrastructure components are identified and continuously monitored
- Continuous service provision is a continuum of advance capacity planning, acquisition of high-availability components, needed redundancy, existence of tested contingency plans and the removal of single points of failure
- Action is taken on the lessons learned from actual downtime incidents and test executions of contingency plans
- Availability requirements analysis is performed regularly
- Service level agreements are used to raise awareness and increase co-operation with suppliers for continuity needs
- The escalation process is clearly understood and based on a classification of availability incidents
- The business costs of interrupted service are specified and quantified where possible, providing the motivation to develop appropriate plans and arrange for contingency facilities
Scope
In Scope
- Identifying a required and agreed to minimum level of business operation following a service disruption, along with a requirements definition covering systems, facilities and service requirements.
- Examination of the risks and threats to these requirements and develops an IT risk reduction or mitigation programs.
- Mechanism to deliver the Continuity requirements necessary to provide the required level of business operation.
Usually Excluded
- Longer term risks such as those from changes in business direction, diversification, restructuring, and so on. While these risks can have a material impact on IT Service elements and their Continuity mechanisms, management usually has some time to identify and evaluate the risk and include risk mitigation through changes or shifts in business and IT strategies - thereby becoming part of the Change Management program.
- Minor technical faults (for example, non critical disk failure), unless there is a possibility that the impact could have a material impact on the business. These risks would be expected to be covered mainly through the Service Desk and the Incident Management process, or resolved through the planning associated with the disciplines of Availability Management, Problem Management; and to a lesser extent through Change Management, Configuration Management and 'day to day' operational management.
- The actual Disaster Recovery process itself is not in scope. These processes are designed to ensure readiness for the invocation of the Disaster state. Collecting parameters on the event itself provides information on the success of the processes involved in maintaining readiness.
Assumptions
- The effects of an unknown disaster which causes an outage or disruption to vital services can be mitigated through advance planning of resumption methods for pre-established categories of disasters
- The organization and senior management remain committed to Continuity Planning and Management.
- Continuity Policies will continue to be followed by responsible officials
- Backup processes, people, technologies and facilities will remain available in the event of a disaster.
- Changes within the Business Units in terms of recovery priorities are identified to the Business Continuity Manager.
- Risk management and disaster avoidance measures are used.
Relationship to Other ITIL Processes
Service Level Management
Service level management takes primary responsibility for interfacing with the customer and determining which IT services are most crucial to the survival of the company. Service Continuity Management needs to support them by ensuring recovery scenarios and procedures that will continue to meet the SLA.
Capacity Management
Capacity management ensures that appropriate IT resources are available to meet customer requirements by planning for additional resources as current system resource use begins to near the point of full capacity. Service continuity management has a very close tie to this process, since the contingency plan may outline reduced capacity capabilities in the event of a disaster. These reduced abilities should be clearly outlined in the OLAs that make up the service.
Availability Management
Availability management and service continuity management are closely related as both processes strive to eliminate risks to the availability of IT services. The prime focus of availability management however, is handling the routine risks to availability that can be expected on a day-to-day basis such as the failure of a hardware component. Service continuity management caters to the more extreme and relatively rare availability risks such as fire or flood.
Where no straight-forward countermeasures are available or where the countermeasure is prohibitively expensive or beyond the scope of a single IT service to justify in its own right, then availability management may pass these risks to service continuity management for consideration in the wider context.
Financial Management
Financial management ensures that solutions proposed by service continuity management can be justified in terms of their cost to implement versus their benefits. Financial management strives to monitor, control, and, if necessary, recover costs incurred by the IT organization.
Change Management
As changes are made and accounted for in the Change Management process, the Continuity Management process will need to be reviewed and accessed for any required modifications. Also, as reviews and testing procedures are done through the Continuity Management process, feedback must be made back into the Change Management process.
- A list of survival-critical systems and services will be maintained. Every system and/or service on the list will have a Business Continuity Plan (BCP) and a Disaster Recovery Plan (DRP) developed which will be filed in the Definitive Process Document Library (DPDL) and will be governed by Change Management procedures.
- BCP and DRP will conform to standard organizational policy with regards to developing and maintaining business process descriptions
- BCPs and DRPs will be reviewed annually and whenever significant business or infrastructure changes occur
- Service restoration procedures will be tested at least every two years
- Maintenance of BCPs and DRPs will be negotiated and placed or referenced in SLAs and/or OLAs documenting the obligations of participants and the costs of their administration.
- Testing of a BCP or DRP will be coordinated with amongst departments with whom resources are shared.
| The only way of implementing effective ITSCM is through the identification of critical business processes and the analysis, and co-ordination, of the required Infrastructure and IT supporting services.
|
Business Impact Analysis (BIA)
A key driver in determining ITSCM requirements is how much the organization stands to lose as a result of a disaster or other service disruption and the speed of escalation of these losses. The purpose of a Business Impact Analysis (BIA) is to assess this through identifying:
- critical business processes
- the potential damage or loss that may be caused to the organization as a result of a disruption to critical business processes.
The BIA also identifies:
- the form that the damage or loss may take including lost income, additional costs, damaged reputation, loss of goodwill, loss of competitive advantage
- how the degree of damage or loss is likely to escalate after an service disruption
- the staffing, skills, facilities and services (including the IT Services) necessary to enable critical and essential business processes to continue operating at a minimum acceptable level
- the time within which minimum levels of staffing, facilities and services should be recovered
- the time within which all required business processes and supporting staff, facilities and services should be fully recovered
The latter three items provide the drivers for the level of ITSCM mechanisms that need to be considered or deployed. Once presented with these options, the business may decide that lower levels of service or increased delays are more acceptable based upon a cost/benefit analysis.
These definitions and their components enable the mapping of critical service, application and Infrastructure components to critical business processes, thus helping to identify the ITSCM elements that need to be provided. The business requirements are ranked and the associated ITSCM elements confirmed and prioritized in terms of risk assessment/reduction and recovery planning.
Impacts are measured against particular scenarios for each business process such as an inability to settle trades in a money market dealing process, or an inability to invoice for a period of days.
The impact analysis concentrates on the scenarios where the impact on critical business processes is likely to be greatest. This process enables a business to understand at what point the unavailability of a service would become untenable. This in turn allows the types of ITSCM mechanisms that are most appropriate to be determined to meet these business requirements. It is also important to understand how impacts may change over time. For instance, it may be possible for a business to function without a particular process for a short period of time, for example invoicing, but over a longer period re-establishment will become critical, i.e. in order to maintain cash flow to pay bills and staff.
In the majority of cases, business processes can be re-established without a full complement of staff, systems and other facilities, and still maintain an acceptable level of service to clients and Customers. The business recovery objectives should therefore be stated in terms of the time within which a pre-defined team of core staff and stated minimum facilities must be recovered the timetable for recovery of remaining staff and facilities.
It may not always be possible to provide the recovery requirements to a detailed level. There is a need to balance the potential impact against the cost of recovery to ensure that the costs are acceptable The recovery objectives do, however, provide a starting point from which different business recovery and ITSCM options can be evaluated.
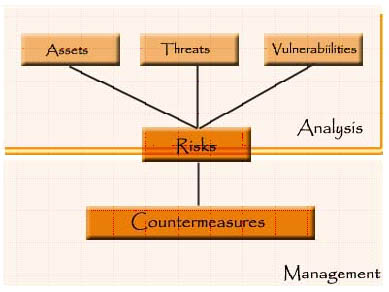 This is an assessment of the level of threat and the extent to which an organization is vulnerable to that threat. if an organization's assets are highly valued and there is a high threat to those assets and the vulnerability of those assets to those threats is high, there would be a high risk. Countermeasures are applied to manage the business risks by protecting the assets.
This is an assessment of the level of threat and the extent to which an organization is vulnerable to that threat. if an organization's assets are highly valued and there is a high threat to those assets and the vulnerability of those assets to those threats is high, there would be a high risk. Countermeasures are applied to manage the business risks by protecting the assets.
As a minimum, the following risk assessment activities should be performed:
The impact of several systems becoming unavailable, and requiring backup support services must be considered as a secondary impact of any particular event. Unless a process is completely isolated, any outage will cause an impact on adjacent systems via a 'ripple effect'.
Following the Risk Analysis it is possible to determine appropriate countermeasures or risk reduction measures to manage the risks, i.e. reduce the risk to an acceptable minimum level or mitigate the risk.
Risk Assessment Tools
Generally, a risk assessment framework has three goals:
- Enable the company to better manage risk and reduce loss.
- Strengthen customer service and shareholder value.
- Meet a variety of regulatory requirements, including internal control assessment and attestation (e.g. those required by Sarbanes-Oxley Section 404.)
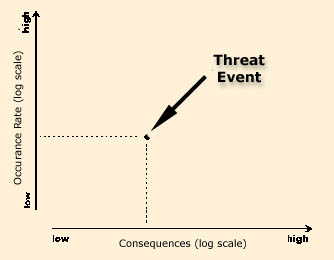
| Risk assessment tools are available to assist with the first of these goals. The risk models within these tools generally operate by collecting information about threats, functions and assets, and the vulnerabilities of the functions and assets to the threats to calculate the consequences, dollar losses, of occurrences of the threats.
When a threat impacts a function or asset, it generates a loss equal to the loss potential (the worst case loss) of the function or asset multiplied by the vulnerability (0.0 to 1.0, the worst case) of the function or asset to the threat. The consequence for a threat is the sum of all of the individual losses. We can plot the occurrence rate and consequence of a threat.
|
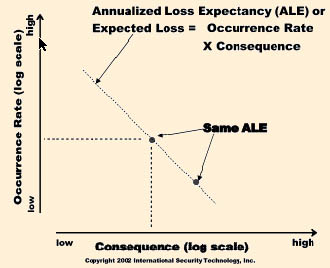
| The vertical scale is the estimated occurrence rate of the threat, e.g., 10 times per year, once every five years, etc. The horizontal scale is the calculated consequence of an occurrence of the threat in dollars. The resulting point on the plot represents the threat event. Note that both scales are logarithmic. We can add a line to the plot to represent the Annualized Loss Expectancy (ALE) or Expected Loss of the threat event. For example if the occurrence rate of a threat is 1/5 (once in five years), and the consequence is $50,000, the threat's ALE is $10,000/year. Plotting this shows the ALE line for the threat event. Since the two scales are logarithmic, contours of constant ALE are straight lines. All threat events that lie on a given ALE contour have the same ALE. In other words, over the long tern these threats will trigger the same total losses. We can use this threat events plot to classify the threat events in terms of the appropriate risk management strategy to apply to each of the threat events.
|
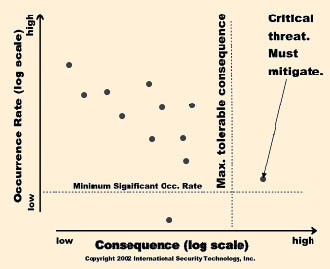
| Begin the classification by dismissing threats for which the estimated occurrence rate is less than a "minimum significant occurrence rate" threshold that are established for the organization. For example, senior management may decide as a matter of policy to ignore threats with an estimated occurrence rate less frequent than once in 100,000 years. Threats that fall below the threshold can be ignored.
Next, senior management should also define the "maximum tolerable consequence" threshold. The value of the threshold consequence may be based on a loss that would bankrupt a private sector organization, or generate an unacceptable drop in the share price. If a threat lies to the right of the threshold, we must take action to either reduce it consequence, or its occurrence rate. Notice that an insurance policy that allows us to claim compensation when a threat event occurs has the effect of reducing the consequence of the threat by "transferring" a portion of the risk to the insurance - at the cost of the insurance policy's premium.
Because these threat events are so infrequent, it is difficult to develop credible estimates of occurrence rate. Notice, however, that our treatment of these threats is governed by their consequences, which can be estimated with reasonable accuracy. Thus, the uncertain occurrence rate estimate does not have a material affect our risk management decisions.
|
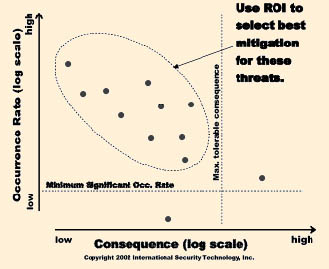
| Finally, we direct our attention to the threats above and to the left of the two thresholds as illustrated to the right.
Since these threats have tolerable consequences, we should only take action when the action will improve the position of our organization. In other words, we want to find an action, which costs $100 to implement, but which we expect will reduce the ALE of the threats by $1,000, not the other way around. The organization needs to define potential mitigation measures in terms of:
- the cost to implement and maintain, and
- the effect the mitigation measure is expected to have on threat occurrence rates and vulnerabilities
|
Disaster Recovery Methods
Recovery options need to be considered for:
- People and accommodation - including alternative premises either owned, leased or through agreement with a third party; reciprocal arrangements with other organizations; and rapid procurement of alternative premises or refurbishment of existing premises. Consideration should also be given to the respective location of the proposed premises, the mobility of the staff who will be supporting the recovered business operations including IT staff and the total number of staff required to support the business process.
- IT systems and networks - these options need to be identified and agreed by the IT Manager responsible for ITSCM and include recovery of IT systems, hardware, applications, software and networks, and the data used within these systems and facilities. This relies on the Availability of effective backups to enable restoration of the service and needs to be performed in collaboration with Availability Management. This strategy should also include the implementation of Continuity mechanisms to support local disruption/interruption of IT Services supporting critical business processes, such as disk mirroring, UPS or dual power supplies, dual communication links, etc.
- Critical services - power, telecommunications, water, couriers and post.
- Critical assets - paper records and reference material.
There may be a need to consider different options for short-term and long-term recovery. Where business processes are highly dependent on external service providers, there is a need to consider the options to address failure of, or peak contention for, the services.
The costs and benefits of each option need to be analyzed. This involves a comparative assessment of the:
- ability to meet the business recovery objectives
- likely reduction in the potential impact
- costs of establishing the option
- costs of maintaining, testing and invoking the option
- technical, organizational, cultural and administrative implications against
- the risk of disruption or disaster and the potential impact if no action is taken
When undertaking analysis, there are a number of basic options that will arise:
Do nothing
Few, if any, organizations can function effectively without IT Services. Even if there is a requirement for stand-alone PC processing, there is still a need for recovery to be supported.
Manual Work-arounds
IT facilities enable organizations to process information much more quickly and efficiently. In financial organizations, complex calculations are undertaken by applications which would be difficult to reproduce manually in a short period of time. They are dependent upon a succession of calculations by different systems with information fed between them from external sources. Manual contingent actions can, however, be an effective interim measure until the IT Service is resumed.
Gradual Recovery (Cold Standby)
can function for a period of up to 72 hours, or longer, without a re-establishment of full IT facilities
Effort may include the provision of empty accommodation fully, equipped with power, environmental controls and local network cabling Infrastructure, telecommunications connections, and available in a disaster situation for an organization to install its own computer equipment.
The accommodation may be provided commercially by a third party, for a fee, or may be private, (established by the organization itself) and provided as either a fixed or portable service.
A fixed facility may be located at the premises of the third party that provides the service, or specially built at a location owned by the subscriber. There is a need to ensure that all services including telecommunications, market data feeds, etc. are established and adequate accommodation is available to house staff involved in the recovery process.
A portable facility is typically a pre-fabricated building provided by a third party and located when needed at a predetermined site agreed with the organization. This may be in a car park or another location some distance from the home site, perhaps, another owned building.
The organization calls on contracts for the supply of required computer equipment including PCs, servers, and mini computers. The organization or the contractor (whichever has been formally pre- agreed) then configures the equipment to the organizational requirements and loads all data before a service can be provided.
Third parties rarely guarantee replacement equipment within a fixed deadline, but would normally do so under their best efforts.
When opting for a gradual recovery, consideration must be given to highly customized items of hardware or equipment that will be difficult, if not impossible, to replace if no spares are kept securely by the organization. Other contingency measures may be needed to cope with having to use different equipment. The same difficulties apply to items supplied by organizations that have since gone out of business and alternatives need to be identified, possibly putting the Service Delivery at risk due to delays or potential Problems.
Intermediate Recovery (Warm Standby)
re-establish the critical systems and services within a 24 to 72 hour period
Most common is the use of commercial facilities, which are offered by third party recovery organizations to a number of subscribers, spreading the cost across those subscribers. Commercial facilities often include operation, system management and technical support. The cost varies depending on the facilities requested such as processors, peripherals, communications, and how quickly the services must be restored (invocation timescale).
The advantage of this service is that the Customer can have virtually instantaneous access to a site, housed in a secure building, in the event of disaster. It must be understood, however that the restoration of services at the site may take some time as delays may be encountered while the site is re-configured for the organization that invokes the service, and the organization's applications and data will need to be restored from backups.
There is a disadvantage in that the site is almost certainty some distance from the home site, which presents a number of logistical problems. The positions are shared (usually up to 20 to 30 times) with other organizations so there can be no guarantee of Availability if a service disruption were to affect two organizations at the same time. There is a need to ensure that a recovery organization is not providing the same services for firms within an immediate geographical area. This is well understood by the recovery organizations, who apply good Risk Management to the sale of the positions in order to reduce the risk of multiple invocations. It is also a fairly expensive option and can be likened to insurance. What is being paid for is peace of mind. In recent years the number of recovery centers has increased considerably and, together with the falling cost of computer hardware, good deals can be negotiated for 3, 5, or 7-year contracts.
If the site is invoked, there is often a daily fee for use of the service in an emergency, although this may, be offset against additional cost of working insurance. Most commercial agreements limit invocation access to a pre-determined length of time, typically between 6 to 12 weeks and therefore longer term options are also required.
It is important that any arrangements of this sort include adequate opportunity for testing at the contingency site.
Immediate Recovery (Hot Standby)
immediate restoration of services
The immediate recovery is supported by the recovery of other critical business and support areas during the first 24 hours following a service disruption. Instances where immediate recovery may be required are where the impact of loss of service has an immediate impact on the organization's ability to make money, such as a Bank's dealing room.
Where there is a need for a fast restoration of a service, it is possible to 'rent' floor space at the recovery site and install servers or systems with application systems and communications already available and data mirrored from the operational servers. In the event of a system failure, the Customers can immediately switch to the backup facility with little or no loss of service.
In the case of building loss or denial of access an organization can pay for a limited number of exclusive positions at a recovery centre. This is a highly expensive option and is not appropriate for the majority of organizations. However, these positions are always available and ready for immediate occupation and use.
Some organizations may identify a need for their own exclusive immediate recovery facilities provided internally. This again is an expensive option but may be justified for a certain business process where non-Availability for a short period could result in a significant impact. The facility needs to be located separately and far enough away from the home site that it will not be affected by a disaster affecting that location.
For highly critical business processes, a mirrored service can be established at an alternative location, which is kept up to date with the live service, either by data transfer at regular intervals,or by replications from the live service. Such a service could be used merely as a backup service, but it might also be used for enquiry access (such as reporting) without affecting the live processing performance. This is also useful if there are legal or legislative obligations to safeguard the completeness and integrity of all financial records. As this is essentially spare Capacity, under normal circumstances this spare Capacity can be used for development, training or testing, but could be made available immediately when a Service Continuity situation demands it.
The ultimate solution is to have a mirrored site with duplicate equipment as part of the live operation. However, these mirrored servers and sites options, should be implemented in close liaison with Availability Management.
Invocation of Disaster Recovery Plan (DRP)
DRP planning must include procedures and guidelines for its invocation. Invoking these procedures should not be taken lightly. Costs will be involved and the process will involve disruption to the business. This decision is typically made by a 'crisis management team' comprising senior managers from the business and support departments (including IT) using information gathered through damage assessment and other sources.
A disruption could occur at any time of the day or night, so it is essential that guidance on the invocation process is readily available. Plans must be available both in the office and at home and key members of the crisis management team should be issued with a short reminder which they must keep with them at all times detailing:
- the locations of these plans
- the associated key actions and decision points
- contact details of the crisis management team
The decision to invoke must be made quickly, as there may be a lead-time involved in establishing facilities at a recovery site. In the case of a building fire, the decision is fairly easy to make, however, in the case of power failure, where a resolution is expected within a short period, a deadline should be set by which time if the crisis has not been resolved, invocation of the DRP will take place. This deadline will be established by the crisis management team - working back from the critical point by which the business processes must be re-established to prevent an unacceptable impact to the organization.
Continuity Planning
A Continuity Plan is developed to support critical business functions. The Continuity Plan includes event notification, escalation, and execution of the plan. A project plan identifies dependencies and/or potential bottlenecks. Clearly written recovery procedures are defined to address the most likely scenarios. The plan will be tested and reviewed regularly by the business continuity manager.
Continuity services may include:
- standby servers and workstations
- facilities management of equipment
- telecommunications facilities
- standby call centre facilities
- data vaulting/off site data replication
- web server hosting
- data warehousing
Business Continuity Manager
- Owns the Service Continuity process
- Liaison to senior management
- Responsible for Business Continuity Plan
- Communicate and maintain awareness
- Integrate process across organizations
Availability Manager
The Availability Manager is responsible for ensuring that any given IT service delivers the levels of availability agreed with the customer and for interfacing with all other management processes in pursuit of this goal.
The Availability Manager :
- Ensures customer requirements are correctly translated into realistic availability goals
- Ensures appropriate IT budgets are established for protecting the service
- Oversees planning activities in relation to designing for availability and designing for recovery
- Ensures that all risks to availability are identified and appropriately handled
- Undertakes availability modeling to help select the most appropriate countermeasures, assesses the impact of future changes, and identifies potential improvements
- Implements cost-effective countermeasures to single points of failure where possible
- Ensures that remaining gaps are identified to the customer and ultimately handled by service continuity management when required
- Manages the day-to-day availability requirements of services
- Manages a continuous availability improvement process
Crisis Management Team
- Committee of Senior Leadership Team representatives
- Convenes to evaluate damage assessment reports
- Determine the appropriateness and scope of a disaster declaration
- Invoke disaster recovery actions an/or begin emergency response activities
- Communicates any disaster declarations
Recovery Teams
- Carry out the actions that are required for recovery from a disaster, each with its own area of responsibility. For each respective business function, there is a team of 5-7 people. There will also be a team lead and a backup to the team lead.
- The recovery teams operate under a management team that oversees, and co-ordinates recovery efforts. Each team is defined based upon their role in managing system availability and business continuity.
- Ensure that the system configurations and the associated network requirements are accurate and technically feasible at all times.
Key Goal Indicators
- No incidents causing public embarrassment
- Number of critical business processes relying on IT that have adequate continuity plans
- Regular and formal proof that the continuity plans work
- Reduced downtime
- Number of critical infrastructure components with automatic availability monitoring
Key Performance Indicators
- Number of outstanding continuous service issues not resolved or addressed
- Number and extent of breaches of continuous service, using duration and impact criteria
- Time lag between organizational change and continuity plan update
- Time to diagnose an incident and decide on continuity plan execution
- Time to normalize the service level after execution of the continuity plan
- Number of proactive availability fixes implemented
- Lead time to address continuous service shortfalls
- Frequency of continuous service training provided
- Frequency of continuous service testing
Measurement Issues
Since Service Continuity is all about providing insurance in the event of a disaster, it is often extremely difficult to ensure attention and funding are devoted to measuring the success of this readiness. ( Despite average revenue in excess of $1-billion for Fortune 1000 companies, more than 40 percent of them spent less than $1 million per year on security (including DRP)- according to Forrester Research in Cambridge, Mass.) Moreover, most measures in this area are not subject to automation, thereby requiring sustained diligence to record events from multiple sources done intermittently over prolonged periods.
Critical Success Factors
- A no-break power system is installed and regularly tested
- Potential availability risks are proactively detected and addressed
- Critical infrastructure components are identified and continuously monitored
- Continuous service provision is a continuum of advance capacity planning, acquisition of high-availability components, needed redundancy, existence of tested contingency plans and the removal of single points of failure
- Action is taken on the lessons learned from actual downtime incidents and test executions of contingency plans
- Availability requirements analysis is performed regularly
- Service level agreements are used to raise awareness and increase co-operation with suppliers for continuity needs
- The escalation process is clearly understood and based on a classification of availability incidents
- The business costs of interrupted service are specified and quantified where possible, providing the motivation to develop appropriate plans and arrange for contingency facilities
Service Continuity Process Summary
|
| Controls
- Management Constraints & Enrichments
- Service Catlogue/SLA
- Current policies, process & procedures
|
|
Inputs
- Availability Plans
- Business Plans
- Service Level Requirements
- Risks & Threats
- Historical Data
- CMDB
| Activities
| Outputs
- Risk Assessments
- Crisis Management Plan
- Disaster Recovery Plans
- Disaster Recovery Readiness Assessments
|
|
| Mechanisms
- Risk Assessment Techniques
- information Collection
- Questionnaire Design
- Interviewing
|
|
Inputs
Availability Plans
The Availability Plan will describe the availability requirements for business services. Service continuity management typically "picks up where they left off" to address those availability risks that Availability Management cannot or chooses not to address.
Business Plans of Customers
Customer annual business plans provide information on strategic intent. These plans form the basis for planning activities to support and align with this business intent. Financial Management provides advice and assistance in developing cost scenarios, alternatives and feasibility studies associated with these plans.
Service Level Requirements (SLR)
SLRs should be an integral part of the service design criteria, of which the functional specification is a part. They should, from the very outset, form part of the test/trial criteria as the service progresses through the stages of design and development or procurement. A draft SLA should be developed alongside the service itself, and should be signed and formalized before the service is introduced into live use.
Risks and Threats
Historical Data
CMDB
Controls
Management Constraints/Enrichment
Management financial constraints will impose controls or afford opportunity on the exercise of service continuity activities by restricting or enriching resources available.
Service Catalogue - Service Level Agreements
Service Catalogue and SLAs contain information related to the current cost of services and the negotiated level of performance associated with them. They provide baseline information to cost service modifications or, in conjunction with performance data, to explain financial variances.
Current Policies, Processes and Procedures
Mechanisms
Risk Assessment Techniques
Threat-Risk Assessments of the relevant information risks to the achievement of the business objectives form a basis for determining how the risks should be managed to an acceptable level. These should provide for risk assessments at both the global level and system specific levels (for new projects as well as on a recurring basis) and should ensure regular updates of the risk assessment information with results of audits, inspections and identified incidents.
Information Collection - Risk Self-assessment Meetings
Facilitated self-assessment sessions can include risk, control, or process assessment sessions as well as strategic/creative meetings, such as strategic planning sessions. For different types of sessions you may use a different meeting structure. However, all types of sessions employ a "group process" approach to seeking input, and all types of sessions, therefore, have certain elements in common.
Questionnaire Design
Interviewing
Outputs
Risk Assessments
Sound risk assessments are critical to establishing an effective continuity plan. The risk assessment provides a framework for establishing policy guidelines and identifying the risk assessment tools and practices that may be appropriate for an institution.
Examples of items to consider in the risk assessment process include:
- Identifying survival-critical information systems, and determining the effectiveness of current information security programs. For example, a vulnerability might involve critical systems that are not reasonably isolated from the Internet and external access via modem. Having up-to-date inventory listings of hardware and software - as well as system topologies - is important in this process.
- Assessing the importance and sensitivity of information, and the likelihood of outside break-ins (e.g., by hackers) and insider misuse of information. For example, if a large depositor list were made public, that disclosure could expose the bank to reputational risk and the potential loss of deposits. Further, the institution could be harmed if human resource data (e.g., salaries and personnel files) were made public. The assessment should identify systems that allow the transfer of funds, other assets, or sensitive data/confidential information, and review the appropriateness of access controls and other security policy settings.
- Assessing the risks posed by electronic connections with business partners. The other entity may have poor access controls that could potentially lead to an indirect compromise of the bank's system. Another example involves vendors that may be allowed to access the bank's system without proper security safeguards, such as firewalls. This could result in open access to critical information that the vendor may have "no need to know."
- Determining legal implications and contingent liability concerns associated with any of the above. For example, if hackers successfully access a bank's system and use it to subsequently attack others, the bank may be liable for damages incurred by the party that is attacked.
Crisis Management Plan
The Crisis Management Plan is designed to ensure the continuation of vital business processes in the event that an emergency or crisis situation should occur. Should an emergency situation occur at any business location, the plan should provide an effective method that can be used by management personnel to control all activities associated with a crisis situation in a pro-active manner and to lessen the potential negative impact with the media, the public and with shareholders. This plan should be updated annually and should always be readily available to authorized personnel.
This plan is designed as a companion document to the Business Resumption Plan- which consists of two major parts, each a recovery plan.
- the Disaster Recovery Plans for technology in the event that a disaster should strike data processing center(s).
- The second is the Business Recovery Plan that will address issues surrounding the business operation and business units should a disaster affect.
The Business Resumption Plan should document the responsibilities, procedures, and checklists that will be used to manage and control the situation following an emergency or crisis occurrence.
The Crisis Management Plan should:
- Prepare senior management personnel to respond effectively in a crisis situation
- Manage the crisis in an organized and effective manner
- Limit the magnitude or impact of any crisis situation to the various business units.
Crisis Management Plan activities are initiated by a situation or crisis alert procedure. After discovery of an incident, the Crisis Management Team will perform an assessment of the situation and determine if there is a need to declare an emergency or crisis and activate the Crisis Management Plan. When the plan is activated, assigned management personnel will be alerted and directed to activate their procedures.
Disaster Recovery Plans (Created / Updated)
The Disaster Recovery Test Plan includes test parameters, objectives, measurement criteria, test methodology, task plan charts and time lines to validate the effectiveness of the current Disaster Recovery Plan.
The Disaster Recovery Plan will be tested to ensure that the business has the ability to continue the critical business processes in the event of a disaster. It is very important that the Recovery procedures are executable and accurate. Another benefit of testing the plan is to train the personnel who will be responsible for executing the Disaster Recovery Plan.
The important issue is not that the test succeeded without problems, but, that the test results and problems encountered are reviewed and used to update or revise the current Disaster Recovery Plan procedures. Testing can be accomplished by executing the disaster implementation plan or it may be desirable to execute a subset of the plan. When performing a Disaster Recovery Test, it is very important to use only that information which is recalled from the off-site storage facility. This is to ensure the following:
- Simulate the conditions of an actual Disaster Recovery situation
- Completeness of the disaster recovery information stored at the Records Retention Site
- The ability to recover the intended functions
Disaster Recovery Readiness Assessment Audit
Activities
 SCM0 - Service Continuity Management Summary
SCM0 - Service Continuity Management Summary
SCM1 - Develop Service Continuity Framework
The scope of the Continuity Plan is defined and is reviewed by business managers. The type of disasters the Continuity Plan needs to address are established. Business impacts are typically defined into categories according to predefined criteria such as revenue loss, lost wages, or company image.
SCM2 - Conduct Risk and Disaster Avoidance Assessment
It is important to practice risk and avoidance management to ensure the organization does not assume an unacceptable level of risk.
The current environment is evaluated to ensure measures are in place to avoid potential disasters. Examples include raised floors, physical security, password security, fire suppression systems, and other high-risk threats. Risk Assessment is a process to identify risks and vulnerabilities to the organization and is done in concert with the disaster avoidance review. This will identify threats to the organization and judge the risk of that threat affecting the organization.
The Risk Assessment is the process of identifying the chances of a threat occurring, identify how vulnerable an activity is to each threat, determining how effective a control would be in deterring the threat, and limiting the cost associated with the risk and minimizing the impact that threats may have on the organization.
Threats can be considered one of two types: natural and man-made. Natural threats consist of events such as tornadoes, hurricanes, and earthquakes. Man-made threats include riots, programming error, sabotage, strikes, bombs, and terrorist activity. For each threat, a probability needs to be placed both with and without controls. The organization will then need to determine which risks they are willing to accept and those they want to control.
SCM3 - Business Impact Analysis (BIA)
The BIA is a systematic process that gathers and analyzes information to determine a business's most critical systems and the effect that would result if these systems were disrupted or lost. When looking specifically at software and hardware, the analysis identifies and quantifies the interdependency of IT infrastructures within an organization and the impact of essential applications failures.
The BIA helps to determine what the critical failure points are, and thus, prioritize the most critical areas for restoration. It also reveals the current state of preparedness, the technology and special resources required for recovery, and the expenses necessary to continue operations after a disruption.
A BIA's objective is to document recovery strategy options, and their costs, for consideration by senior management. There are four key questions to consider:
- What functions are critical to my business'/department's operations and why?
- What resources do critical functions use when they are being performed?
- What duration of interruption can these functions withstand?
- How much will it cost to establish a recovery capability that restores the resources needed by critical functions in the time frame they require?
The first question can be answered quickly by most senior managers. Interviews with critical function providers can then establish the specific resources used and how long an interruption can be withstood. With the resource owners, such as IT or facilities groups, professionals can then deliver on strategy options and costs. These must be based on the resources needed by vital business functions in the time frames function providers deem necessary.
The aim of DRPs is to establish proactive, recovery capabilities to ensure delivery of critical services and products in spite of the circumstances. Such planning must be based on a cost-benefit approach.
SCM4 - Determine Backup Options
Based upon the requirements for recovering critical functions, a variety of backup options may be chosen. Options are not exclusive and the use of an option may be dependent on the type of disaster or interruption occurring. The goal is to apply the appropriate backup options for specific critical functions.
Backup recovery strategies are alternative operating methods for facilities and system operations in the event of a disaster. The recovery alternative is the method selected to recover the critical business functions following a disaster. Possible choices would be manual processing, use of outside service provider, or a standby backup site. A recovery alternative is usually selected following a Risk Analysis and/or Business Impact Analysis.
An alternate site is defined as a location, other than the primary facility, used to process data and/or conduct critical business functions in the event of a disaster. The recovery capability is defined as all components necessary to perform recovery. These components can include a plan, an alternate site, change control process or network rerouting. For each area of the Continuity Plan, there may be multiple options including business units, IT, users, call centers, etc.
SCM5 - Design and Develop
The intention of the Business Impact Analysis (BIA) is to enumerate assets, how they may become absent or limited, and how this would affect the fulfillment of business objectives. Based on the findings of the BIA, a Business Continuity Plan (BCP) must be developed to detail contingency measures to operate with, and recover from, an absence or loss of assets. Ultimately assets will be replaced or recovered and full operations will resume, as detailed in the Disaster Recovery Plan (DRP).
The planning of recovery procedure centers on establishing recovery teams and specifying their responsibilities. The structure of Recovery Teams must reflect the organization. For each team, there should be a team leader, an alternate team leader, and team members. Each Team should have a charter defining roles and responsibilities describing the actions that must be taken to bring about recovery from a disaster. Each team charter defines specific recovery procedures relevant to the infrastructure components for which they are responsible.
The specification of these components and their recovery plans can be associated with the Configuration Item (CI) and listed in the CMDB. The reference can direct a Service Desk or Availability Analyst to a set of processes maintained in the Definitive Process Documents Library (DPDL). The CI may also have references to records in an Availability Management database (AMDB) where information on current and expected future availability (e.g. MTBF) is maintained.
Once developed, the DRP should be reviewed annually,, and a quarterly Disaster Recovery Readiness Assessment Audit should be conducted as well. The purpose of the reviews and the audits is to identify any changes to ensure that these and any other updates identified since the previous review have been captured.
SCM6 - Review and Revise Plan
The contents of the Continuity disaster recovery plan must be reviewed according to a predefined schedule. In addition to regular reviews of the plan, it should also be updated as part of the change management process and with other related changes. There should also be an independent audit of the Plan to ensure it meets specifications as determined by an objective body.
The Corporate Change Management should be involved with changes or updates as made to the recovery plan, and, as changes are made to the infrastructure which may affect the CIs involved in the DRP, the Change Manager should notifying the Continuity Manager.
Items to be reviewed for Plan update should include:
- Personnel changes
- Mission changes
- Priority changes
- New Business Organizations
- Mainframe and Mid-range Disaster Recovery Test procedures and results
- Backup procedures
- Recovery procedures
- Relocation / Migration Plan
- Software (operating system, utilities, application programs)
- Hardware (mainframe, mid-range and peripherals)
- Communications Network Facilities
Particular attention should be paid to the review of the recovery equipment configurations to ensure that the business has the required equipment to restore the business functionality as quickly and smoothly as possible.
A post test review should be conducted to discuss issues encountered during the testing and to direct amendments to DRP and/or Testing documentation. This documentation should be under Change Management so that any modification to the plan will require a Request for Change (RfC) - recognizing any delegations of this kind of revision to the appropriate Local Change Agent - including any pre-authorization which may be in effect.
Service Continuity Planning for Critical Functions
Each critical function is originally evaluated and annually reviewed to assess alternate processing procedures for the period between a disaster and its' recovery and whether the recovery requires an alternate backup site or can be handled within the on-site data center.
For selected critical applications, alternate processing procedures are designed and developed for use until computer facilities are restored, whether on or off-site. If alternate procedures are used, it is necessary that the procedure(s) maintain continuity of the data. No information should be lost as a result of the alternate procedures, and there must be a way to integrate data from the alternate procedure into the usual system when processing is restored. The alternate procedure outlines step-by-step how to process the critical function using different means. The alternate procedure includes integrity checks, timelines, thresholds, and rehearsal plans. It also includes update and maintenance procedures.
Continuity and Disaster Recovery Training
DRP training is needed to make sure that the right people get the right kind of training. Training needs to be tailored to the varied tasks which may be required of members of the Recovery Team. The Training Plan should be specific, clear, and complete. It should include objectives, programs, schedule, and administrative requirements. Forms, checklists, ratings, and other tools should be used to guide the training program.
Terms
| Term | Definition
|
| Alternate Procedures | Methods to process an application or function without the normal data center facilities. In some cases, these will be entirely manual procedures or by using a PC-based system.
|
| Availability | Ability of a component or service to perform its required function at a stated instant or over a stated period of time. It is usually expressed as the availability ratio, i.e. the proportion of time that the service is actually available for use by the Customers within the agreed service hours.
|
| Baseline | The present state of performance, from which changes to services can be reviewed.
|
| Business Continuity Plan | Also called contingency planning, determines how a company will keep functioning until its normal facilities are restored after a disruptive event. This encompasses how employees will be contacted, where they will go and how they will keep doing their jobs.
|
| Business Interruption | Any event which disrupts the normal course of business operations.
|
| Business Impact Analysis (BIA) | The identification of the effect on the organization of the risks to it, should they occur.
|
| Business Resumption Plan | A composite document comprising two major parts, each a recovery plan. The first are the Disaster Recovery Plans for technology in the event that a disaster should strike data processing center(s). The second is the Business Recovery Plan that will address issues surrounding the business operation and business units should a disaster affect.
|
| Business Recovery Plan | Companion document to the Disaster Recovery Plan, which addresses issues surrounding the business operation and business units should a disaster affect.
|
| Capacity | Everything that is required for delivering the performance agreed on with the client at an optimal service level and cost.
|
| Capacity Management | Processes designed to ensure that IT processing and storage capacity match the evolving demands of the business in the most cost-effective and timely manner.
|
| Capacity Plan | The capacity plan documents current levels of resource utilization and service performance. After consideration of business requirements, it forecasts future requirements for resource for IT services that support the business. The capacity plan recommends resource levels required and changes to accomplish operating level objectives in support of the SLA. It includes their cost, benefit, reports of their compliance to IT SLA, their priority and impact to the overall business and the IT infrastructure.
|
| Change Advisory Board (CAB) | A group of people who can give expert advice to the Change Manager on the implementation of Changes. The rigor with which changes are considered is determined by the evaluated risk associated with the change. The degree of risk (as well as customer concerns and financial considerations) will determine the authority charged with approving changes into the infrastructure.
|
| Change Calendar | A documented record of the sequence of steps involved in building a release (implementing a change).
|
| Change Management | Process of controlling Changes to the infrastructure or any aspect of services, in a controlled manner, enabling approved Changes with minimum disruption.
|
| Configuration Item (CI) | Component of an infrastructure - or an item, such as a Request for Change, associated with an infrastructure - that is (or is to be) under the control of Configuration Management.CIs may vary widely in complexity, size and type, from an entire system (including all hardware, software and documentation) to a single module or a minor hardware component.
|
| Configuration Management Database (CMDB) | A database that contains all relevant details of each CI and details of the important relationships between CIs.
|
| Continuity | The ability to respond to an interruption in services by implementing a disaster recovery plan to restore the organization's critical business functions.
|
| CRAMM | CCTA Risk Analysis & Management Method, used to obtain a comprehensive view of potential risks to the IT installation or IT systems by undertaking a formal review of security. CRAMM asserts that risk is dependent on the asset values, the threats, and the vulnerabilities. The values of these parameters are assessed by the CRAMM practitioner in a series of interviews with the owners of the assets, the users of the system, the technical support staff, and the departmental security officer. The outcome of a CRAMM review is a set of recommended countermeasures that are deemed necessary to combat the risks in protecting the information.
|
| Crisis | A critical event, which, if not handled in an appropriate manner, may dramatically impact an organization's profitability, reputation, or ability to operate.
|
| Crisis Alert Procedure | Formal processes and activities for the declaration of a crisis situation.
|
| Crisis Management Plan | Designed to ensure the continuation of vital business processes in the event that an emergency or crisis situation should occur. Should an emergency situation occur at any business location, the plan should provide an effective method that can be used by management personnel to control all activities associated with a crisis situation in a pro-active manner which lessens potential negative impacts.
|
| Critical Functions | See Vital Business Functions
|
| Critical Success Factor (CSF) | Critical Success Factors - the most important issues or actions for management to achieve control over and within its' IT processes.
|
| Customer | Payer of a service; usually theCustomer management has responsibility for the cost of the service, either directly through charging or indirectly in terms of demonstrable business need.
|
| Definitive Process Document Library (DPDL) | A documents repository where the current and archived copies of process descriptions are retained. The current operational process description should be available for quick reference via an intranet web portal.
|
| Disaster | Any event that creates an inability on the organization to provide critical business functions for some predetermined period of time.
|
| Disaster Recovery Plan (DRP) | A document describing procedures for the proactive, recovery of critical services and products in the event of a defined outage of the vital service functions associated with that service or product.
|
| Emergency | A sudden, unexpected event requiring immediate action due to a potential threat to health and safety, the environment, or property.
|
| Environment | A collection of hardware, software, network and procedures that work together to provide a discrete type of computer service. There may be one or more environments on a physical platform e.g. test, production. An environment has unique features and characteristics that dictate how they are administered in similar, yet diverse, manners.
|
| Key Business Driver | The attributes of a business function that drive the behaviour and implementation of that business function in order to achieve the strategic business goals of the company.
|
| Gradual Recovery (cold stand-by)
| A disaster recovery strategy which is applicable to organizations that do not need immediate restoration of business processes and can function for a period of up to 72 hours, or longer, without a re-establishment of full IT facilities. This may include the provision of empty accommodation fully equipped with power, environmental controls and local network cabling infrastructure, telecommunications connections, and available in a disaster situation for an organization to install its own computer equipment.
|
| Immediate Recovery (hot stand-by) | A disaster recovery strategy which provides for the immediate restoration of services following any irrecoverable incident. It is important to distinguish between the previous definition of 'hot standby' and 'immediate recovery'. Hot standby typically referred to availability of services within a short timescale such as 2 or 4 hours whereas immediate recovery implies the instant availability of services.
|
| Impact Analysis | The identification of critical business processes, and the potential damage or loss that may be caused to the organization resulting from a disruption to those processes.
|
| Line of Business (LOB) | A part of an organization that functions as separate business entity when viewed from the highest level.
|
| Maximum Acceptable Outage(MAO) | The time it take before the impact of an outage begins to harm the organization. The length of time depends in part on the process and in part on the industry. In real time financial operations, the time window may be minutes. For other organizations, it may be days or even weeks. The impact analysis has to identify what this time window is by which recovery has to be in place.
|
| Metric | A data element that indicates something about the behavior of a system, subsystem, application or process.
|
| Performance | A measure of the responsiveness of the application to interactive users and the time required to complete a transaction.
|
| Process | A connected series of actions, activities, Changes etc. performed by agents with the intent of satisfying a purpose or achieving a goal.
|
| Process Control | The process of planning and regulating, with the objective of performing a process in an effective and efficient way.
|
| Recovery Time | The period from the declaration of a disaster to the recovery of critical functions.
|
| Request for Change (RFC) | Form, or screen, used to record details of a request for a Change to any CI within an infrastructure or to procedures and items associated with the infrastructure.
|
| Risk | A measure of the exposure to which an organization may be subjected. This is a combination of the likelihood of a business disruption occurring and the possible loss that may result from such business disruption.
|
| Risk Analysis | The identification and assessment of the level (measure) of the risks calculated from the assessed values of assets and the assessed levels of threats to, and vulnerabilities of, those assets.
|
| Risk Management | The identification, selection and adoption of countermeasures justified by the identified risks to assets in terms of their potential impact upon services if failure occurs, and the reduction of those risks to an acceptable level.
|
| Role | A set of responsibilities, activities and authorizations.
|
| Service | An intangible set of benefits provided by one party to another. Services are created by performing certain activities. Services are usually created by a large number of activities that create the benefits together. Each activity contributes directly or indirectly to the set of benefits. Activities that directly create a benefit are called service delivery activities. Activities that indirectly contribute to the delivery of services are called service support activities.
|
A description of the services offered by an organization which can be used to order and describe a service in full.
| Service Level Agreement | A written agreement between a service provider and Customer(s) that documents agreed services and the levels at which they are provided at various costs.
|
| Service Level Management | Disciplined, proactive methodology and procedures used to ensure that adequate levels of service are delivered to supported IT users in accordance with business priorities and at acceptable costs.
|
| Threat | A potentially undesirable event which can cause a loss and have a disastrous impact on the organization.
|
| User | The consumer of a service - the person or group who accesses and uses the service - to be distinguished by the Customer, who Pays for the service (though it may be the same person).
|
| Vital Business Functions (VBF) | Critical areas in a company that are usually involved in revenue generation, customer service or compliance. The assessment of criticality is ultimately made by the leadership of the company and reflects their perspective of what an unacceptable interruption in a business process would be in relation to the overall objectives of the organization.
|
| Vulnerability | Characteristics of an infrastructure's design, implementation, or operation that renders it susceptible to events which can adversely affect functional business elements.
|
Service Continuity Maturity Levels
| 0 Non-existent | There is no understanding of the risks,
vulnerabilities and threats to IT operations or the impact
of loss of IT services to the business. Service continuity
is not considered as needing management attention.
|
| 1 (Initial/Ad Hoc) | IResponsibilities for continuous service
are informal, with limited authority. Management is
becoming aware of the risks related to and the need for
continuous service. The focus is on the IT function,
rather than on the business function. Users are
implementing work-arounds. The response to major
disruptions is reactive and unprepared. Planned outages
are scheduled to meet IT needs, rather than to
accommodate business requirements.
|
| 2 (Repeatable but Intuitive) | Responsibility for
continuous service is assigned. The approaches to
continuous service are fragmented. Reporting on system
availability is incomplete and does not take business
impact into account. There are no documented user or
continuity plans, although there is commitment to
continuous service availability and its major principles
are known. A reasonably reliable inventory of critical
systems and components exists. Standardisation of
continuous service practices and monitoring of the
process is emerging, but success relies on individuals.
|
| 3 (Defined Process) | Accountability is unambiguous and
responsibilities for continuous service planning and
testing are clearly defined and assigned. Plans are
documented and based on system criticality and business
impact. There is periodic reporting of continuous service
testing. Individuals take the initiative for following
standards and receiving training. Management
communicates consistently the need for continuous
service. High-availability components and system
redundancy are being applied piecemeal. An inventory
of critical systems and components is rigorously
maintained.
|
| 4 (Managed and Measurable) | Responsibilities and
standards for continuous service are enforced.
Responsibility for maintaining the continuous service
plan is assigned. Maintenance activities take into
account the changing business environment, the results
of continuous service testing and best internal practices.
Structured data about continuous service is being
gathered, analysed, reported and acted upon. Training is
provided for continuous service processes. System
redundancy practices, including use of high-availability
components, are being consistently deployed.
Redundancy practices and continuous service planning
influence each other. Discontinuity incidents are
classified and the increasing escalation path for each is
well known to all involved.
|
| 5 Optimized | Integrated continuous service processes are
proactive, self-adjusting, automated and self-analytical
and take into account benchmarking and best external
practices. Continuous service plans and business
continuity plans are integrated, aligned and routinely
maintained. Buy-in for continuous service needs is
secured from vendors and major suppliers. Global
testing occurs and test results are fed back as part of the
maintenance process. Continuous service cost
effectiveness is optimised through innovation and
integration. Gathering and analysis of data is used to
identify opportunities for improvement. Redundancy
practices and continuous service planning are fully
aligned. Management does not allow single points of
failure and provides support for their remedy.
Escalation practices are understood and thoroughly
enforced.
|
