| | 
|
Problem Management
Table of Contents
|
|
|
Problem Management is responsible for the ongoing integrity of the IT environment within the dictates of sound financial management. This requires decisions on whether it is acceptable to allow infrastructure faults and error to continue or to seek their removal from the environment. This integrity includes the ability to remove faults expeditiously and to prevent their appearance and overall impact if it is deemed expedient to permit them to remain in the infrastructure. Problem Management is responsible for the integrity of knowledge bases outlining the state of the infrastructure and methods for treating known problems and errors.
Process Requires Re-writing for conformance with ITIL Version 3.
More...
|
|

|
Introduction to Problem Management
Problem Management is a process within the Service Operation module of the ITIL Service Lifecycle.
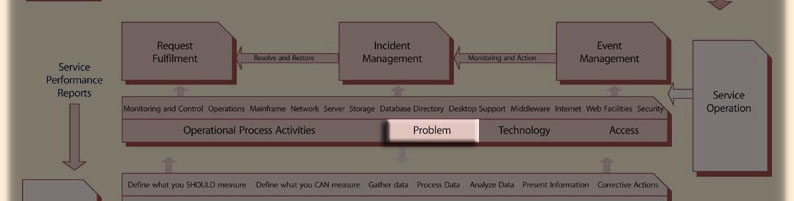
Problem Management differs from Incident Management in that its main goal is the detection of the underlying causes of an Incident and their subsequent resolution and prevention. In many situations this goal can be in direct conflict with the goals of Incident Management where the aim is to restore the service to the Customer as quickly as possible, often through a temporaryWork-around, rather than the implementation of a more permanent resolution -- which may prevent future Incidents from occurring. The speed of service restoral is of paramount consideration in managing incidents, whereas, an investigation of the underlying Problem can require addtional time which will delay the restoration of service (causing downtime but preventing recurrence).
![[To top of Page]](../images/up.gif)
Problem Management
The goal of Problem Management is to minimize the adverse impact of Incidents and Problems on the business that are caused by known errors within the IT Infrastructure, and to prevent recurrence of Incidents related to these known errors. In order to achieve this goal, Problem Management seeks to get to the key factors responsible for Incidents and then initiate actions to improve or correct the situation.
Problem Management can improve the quality of service by significantly reducing the number of incidents and reducing the workload on the IT Support organization. Some of the advantages include:
- Improved IT service quality and management - as known errors are documented and/or eliminated. Problem Management introduces standards for recording of problems and classifications to identify problems and their exhibited symptoms effectively. This also improves required linkages to incident reporting.
- Increased support personnel productivity - as solutions are documented, even less experienced Service Desk Analysts can resolve incidents more quickly and efficiently.
- Improved IT service reputation - because the stability of the services is increased, customers are more likely to entrust the IT organization with new business activities.
- Enhanced management and operational knowledge and learning - Problem Management uses historical incident information that can be reviewed to identify trends, and which can then lead to measures to prevent new incidents. Historical information is also useful for investigation and diagnosis, and when preparing RFCs.
- Improved incident recording - Higher first point of contact (FPOC) resolution rates - as Problem Management makes resolution of incidents more likely as known errors, and work-arounds are made available in a Known Error Database. FPOC support is more likely to be able to resolve incidents.
Critical Success Factors
- clearly defined roles amongst incident, problem, availability and change management
- for Error Control the ability to record and track known errors in a data repository
- for proactive Problem Analysis proper coding of Incident data is crucial to enabling analysis of incident patterns and trends
- Training is provided to support personnel in problem resolution techniques (eg. Root Cause Analysis, Kepner-Tregoe
Problem Management deals with the identification, management, and resolution of problems that affect service quality and efficiency. Problem Management begins with the identification of a trend of closed incidents with some commonality or a realization that incidents may be symptoms of a deeper problem in the enterprise systems environment. It includes the tasks and steps required to research the problem and to define a solution.
Scope
Problem Management should ensure these sources are integrated into an organizational approach to Knowledge Management which highlights and builds upon resolution efforts specific to the organization's mixture of technologies and approaches. Problem Management is responsible for maintaining a Knowledge Base outlining Known Errors and problems in the infrastructure and workarounds which can be invoked quickly when they are encountered. This list is augmented with the introduction of defects from Release Management and the base is modified to indicate the removal of faults once a solution is introduced through Change Management into the environment.
In Scope
- Problem Documentation - The Problem Management process is intended to reduce both the number and severity of Incidents and Problems on the business. Therefore, part of Problem Management's responsibility is to ensure that previous information is documented in such a way that it is readily available to First Point Of Contact and other second-line staff.
- Root Cause Analysis -
Problem Management investigates the infrastructure and the available registrations, including the Incident Database, to identify the underlying causes of actual and potential known errors in the provision of services. These investigations are needed because the infrastructure is complex and distributed, and the links between incidents may not be obvious. For example, several known errors may lie at the base of a problem, while several problem definitions may be associated with the same error. First we have to identify a cause. Once the underlying cause has been identified, the problem becomes a known error. A Request For Change (RFC) may then be raised to eliminate the cause. Even after that, Problem Management continues to track and monitor known errors in the infrastructure. For this reason, information is recorded about all identified known errors, their symptoms, and the solutions available.
Where the underlying cause of the Incident is not identifiable then it may be appropriate to raise a Problem record. A Problem is, in effect, indicative of an Unknown Error within the infrastructure. Normally a Problem record is raised only if investigation is warranted. Problem Management generates an RCA, and concludes with a recommendation, which may be a quick fix, a workaround, or a Request for Change (RFC) to a configured item in the environment. Successful processing of a Problem record will result in the identification of the underlying error, and the record can then be converted into a Known Error once a Work-around has been developed, and/or an RFC submitted.
- Defect List Updating of Known Errors - Infrastructure and Application Development staff should be aware of all Known errors and Problems that are associated with the infrastructure and a package or Release. They are required to delete Known errors as they are corrected, but they add any newly introduced known errors from the infrastructure or application development activities themselves, to a revised known errors database or CMDB. Not all Known errors need to be resolved. Their resolution may be too expensive, technically impossible, or require too much time for the business value that the resolution would bring.
Upon implementation of a new Release, this revised known errors database replaces the database of the previous Release as the live version. The cycle then repeats itself as new known errors are discovered in live operation.
- Knowledge Base Responsibility - An important tool in determining root case is the management of knowledge on structural faults and the methods for restoring service when they are encountered. For example, the Microsoft Knowledge Base is a key source for Incidents and known errors associated with Microsoft products as well as driver and product issues with their products. Service support agents should be intimately familiar withy these sources.
Usually Excluded
- Problem Management requires effort and resources and therefore can be expensive. The efforts and costs may not be justifiable in certain types of unmatched Incidents or Incidents with a quick resolution, low impact or low possibility of recurrence. Problem(s) which the problem Analyst decides to forgo consideration of are recorded as unresolved and abandoned.
Discretionary
- Because it has overall responsibility for the existence of errors and their overall impact on the organization, Problem Management has an interest in the resolution of Major Incidents. By making available expertise in root cause analysis and other problem solving technique, they may provide a contribution towards a quicker restoration of service.
Relationship to Other Processes
There is a close Interface between the Problem Management Process and the Incident and Change Management processes. Incident Tickets may reference Problems and Known errors as being inter-related.

Incident Management
Problem Management differs from Incident Management in that its main goal is the detection of the underlying causes of an Incident and their subsequent resolution and prevention. In many situations this goal can be in direct conflict with the goals of Incident Management where the aim is to restore the service to the Customer as quickly as possible, often through a Work-around, rather than through the determination of a permanent resolution (for example, by searching for structural improvements in the IT infrastructure, in order to prevent as many future Incidents as possible). In this respect, therefore, the speed with which a resolution is found is only of secondary (albeit still of significant) importance. Investigation of the underlying Problem can require some time and can thus delay the restoration of service, causing downtime but preventing recurrence.
Change Management
When problem management identifies resolution actions that require changes to configuration items, these changes are implemented under the control of the change management process.
The control provided by the change management process reduces the amount of changes that have to be backed out and ensures that backout plans have been documented in case they are required. The coordinated testing of changes reduces the chance of subsequent incidents caused by the implementation of changes.
Change management also provides problem management with useful information on recent changes, the configuration items affected, and the reason for the changes.
Service Desk
The service desk, with its responsibility for day-to-day coordination of the incident management process, is ideally placed to identify recurrent or multiple incidents that point toward an underlying problem. As such, the service desk is an important source of information for problem management.
In return, problem management works to identify and document workarounds and solutions that the service desk can utilize while performing initial support on new incidents. When resolutions or workarounds are identified by problem management, the information is then passed to users by the service desk.
Problem management also aims to identify information that the service desk can utilize to proactively advise users. In the long run, effective problem management should reduce the number of incidents being reported to the service desk.
Configuration Management
Configuration management provides vital information that is used during the problem management process. The CMDB contains information used to:
- Provide information on CIs.
- Assist with the classification of problems and known errors by indicating services and SLAs impacted by the failure of particular CIs.
- Identify the relationship and dependencies between CIs.
- Identify identical or similar CIs for comparison purposes and to prevent problem replication.
- Identify alternative routes and workarounds.
- Record changes to configuration items as a result of RFCs.
Release Management
Some resolution actions identified by problem management require changes that need to be incorporated and rolled out as releases. These releases are coordinated and managed by the release management process. In order to confirm that the expected resolution has occurred, problem management assesses the release in the production environment to validate that the known error(s) have been permanently fixed.
In a similar way to change management, release management provides the planning, testing, and coordination to roll out these releases without the changes resulting in further incidents.
Capacity Management
The capacity management process identifies capacity-related problems and flags these to problem management.
Problem management often works with the capacity management process in order to plan resolutions for capacity-related problems.
Financial Management
Financial management assists problem management with identifying the costs associated with resolving known errors, as well as not resolving those known errors.
As such, the financial management process is a vital source of information for error control, allowing informed decisions to be made when and if an error should be fixed.
Availability Management
The availability management process works with problem management to propose solutions for the resolution of availability-related problems. Availability management may identify and report availability-related problems to problem management. Additionally, the process assists with the prioritization of problems and known errors by providing information on the cost of loss of availability.
Service Continuity Management
Service continuity management works alongside problem management to propose solutions for the resolution of continuity-related problems. Problem management assists service continuity management with the justification and prioritization of resolution actions. Service continuity management may also report continuity-related problems to problem management.
Security Administration
The security administration function assists problem management by proposing solutions for the resolution of security-related problems. Problem management assists security administration with the justification and prioritization of resolution actions. Service continuity management may also report security-related problems to problem management.
The primary goal of Problem Management is maintaining the integrity of the ’known and trusted state’ of the production infrastructure. The following guidelines will further this endevour:
- There should be a single problem management process, which is separate and distinct from the incident management process. All Problems and their resolutions will be logged in a common Problem Management system which will be made available to Service Desk and Incident Management staff.
- There will be clear linkages between Incident records, Problem records, Known Errors and Requests for Change leveraging existing data systems wherever feasible and practical. Additional interfaces will build upon and interface with existing data sources,
- There will be a definitive and maintained record (ie. a baseline) of the "Known and trusted state" of the infrastructure (ie. a CMDB). All Problem investigations will reference associated Configuration Items maintained in the CMDB,
- The Problem Management process facilitates Root Cause Analysis on incidents (and incident trends or service failures referred to Problem Management by Service Managers, key technical resources and Client representatives). Analysis on the data collected in the Incident Management System database as well as other sources will undergo periodic trend analyses by Problem Management in close consultation with Incident Management staff.
- The Problem Management function is responsible for acting as the service provider for the Knowledge/Known error database and for providing information concerning problems and proposed solutions. Problem Management owns the quality of the knowledge database, and its usability (though they may not responsible for the integrity of the content).
- Incidents referred to Problem Management for Root Cause Analysis will have outcomes documented.
- The Problem Manager will determine appropriate Metrics to be collected to measure the effectiveness and efficiency of the Problem Management process. Performance expectations will be described in Service Catalogue and/or Service Level Agreements.
Smaller organizations are unlikely to have an explicit provision to undertake problem management independent of resolving incidents. While there may be recognition of the need to adopt a workaround as an immediate measure and then work on the cause of the problem as time permits, the fact that the Ticket is probably closed when the service was restored will mean that there is no explicitly recognized timeframe for resolving the underlying cause of the incident.
The first launch into Problem Management activities probably will occur with a post-mortem review of major incidents. During these reviews efforts will be devoted to identifying the underlying cause of the incident so that it can be recorded on the Trouble Ticket and, where required, a change can be initiated to remove any structural faults in the production environment.
IN all but very large organizations, Problem Management analysts will likely be 'requisitioned' from Tier II support for periods of time, either to resolve specific problems or to work on an inventory of Problem Tickets as a part-time but continuing function of their job descriptions. This provides an important career path and allows them to become involved in root cause analysis - what many analysts consider to be the more interesting aspects of their job.
Error Control
 The figure on the right shows the relationship between a problem, known error and RFC, and defines these terms.
The figure on the right shows the relationship between a problem, known error and RFC, and defines these terms.
Escalation frequently changes an Incident into a Known Error and/or a Problem which may or may not result in a Change to the Infrastructure. The sequence of migration of an Incident through Incident and, subsequently, to Problem and Change Management is depicted below.
"Error control" refers to the set of tasks designed specifically to eliminate known errors from the IT environment through the implementation of a change. The tasks that make up the error control activity are shown in the figure to the right. This involves identification, assessment, resolution, continued monitoring, and closure.
This activity is concerned with known errors in both the live and development environments. Development errors are particularly important when releases are implemented in the live environment with known errors. Resolution of all known errors should be handled in the same manner. Since the ultimate resolution of known errors involves implementation of a change, problem management works closely with change and release management during this activity to ensure that each problem is successfully resolved.
Problem Prioritization
In order to direct scarce resources for Service Support most effectively (i.e. to gain the most business benefit from it), it is worthwhile investigating which Problem areas are taking up most support attention. This task is proactive Problem Management. Sev1 failures are the highest priority on the list followed by incidents of lesser priority. Factors that influence priority decisions are:
- the volume of Incidents
- the number of Customers impacted
- the duration and related costs of resolving the Incidents
- the cost to the business - this being perhaps the most important factor of all.
When determining the Impact of a Problem, the relations between components in the IT infrastructure registered in the CMDB can be of great help. By interrogating the CMDB, it is possible to identify CIs that are dependent on part of, or identical to, the CI in the IT infrastructure to which the Incident is applied.
Urgency is the extent to which resolution of a Problem or error can bear delay; it should not be confused with priority.
Priority indicates the relative order in which a series of items - be they Incidents, Problems, Changes or known errors - should be addressed. This will be influenced by considerations of risk and resource availability but is primarily driven by a combination of urgency and impact.
Things affecting Urgency might include:
- the availability of a temporary fix
- the existence of a Work-around
- the possibility of planned delay of resolution
- an awareness of future impact upon the business, e.g. equipment required to support month-end processes.
Problem Manager
- Establish procedures for the problem and error control processes. Ensure a proactive approach to problem management is taken wherever possible and productive. Monitor the efficiency and effectiveness of the problem management process. Maintain integrity of Problem Management tools and documentation
- Facilitate Major incident review meetings and produce documentation, conclusions, recommendations and follow-up items for Problem and Change management consideration
- Ensure periodic audits of the problem management are conducted
- Reviewing the efficiency and effectiveness of Problem Management activities
- Managing the Problem Management support staff
- Training and development of problem management resources
- Review completeness of RCA process
Problem Management
- Coordinate interaction of the problem and incident management processes with the Client Services Manager and Incident Coordinators. Analyze incidents to identify groups of related incidents or trends which may lead to future problems
- Participate in the review of temporary fixes and work-arounds for incidents related to problems and known errors and record them the Remedy Problem Management module.
- Create and submit Requests for Change (RFC) for know known errors to the attention of the Service Manager and Change Coordinator.
- Update Knowledge Databases and knowledge sources for new Known Errors, resolutions to Known Errors, new identified knowledge sources
- Ensure documentation of solutions is easily referenced
- Conduct weekly meetings /or at manager's discretion
- Develop and maintain Problem Management activities
- Review Change Calendar with first point-of-contact manager and incident coordinators
Incident Management
- Escalate Major Incident reviews to Problem Management for follow-up as "problems" and full "root cause" analysis with promotion of appropriate items to "change management" and "lessons learned"
- Review and identify potential problems
- Refer potential problems to the Problem Manager
- Implement preventative measures and provide feedback on their continuing disposition
- Participate in problem management meetings
- Analyze incident records to determine trends or apparent problems that are occurring
Key Goal and Performance Indicators
A measured reduction in the...
- impact of problems on IT resources
- elapsed time from the creation of a Problem Ticket to the recording of its' root cause(s)
- number of Problems with CIs in the production environment
- number of problems avoided through pre-emptive fixes
- number of outstanding known errors per severity level during each measurement interval (generally a rolling four-week period).
Metrics
- Quantity of problem tickets referred over time (monthly/quarterly)
- Quantity of problems where root-cause analysis is waived
- Quantity of problem tickets presently open (without root cause identified)
- Quantity of Known errors in infrastructure
- Quantity of problems assigned to level 2 & level 3
- Mean time tickets were assigned to each level
- Mean time to determine root cause Tickets generated by technology Tickets generated by user group
- Number of Defects placed in production from Release Process
- Average cost of resolving a problem from Problem Ticket creation to root cause determination
Measurement Issues
Measurement is influenced by the means by which an incident is redefined as a problem.
Problem Management Summary Process
|
| Controls
|
|
Inputs
| Activities
| Outputs
- Problem Classification
- Identified Problems
- RFCs
- Updated problem logs
- Updated Knowledge base
- Recommendations
- Reports
|
|
| Mechanisms
- SME Problem Manager
- Problem Management System
- Knowledge Bases
- Technical skill levels
- Problem Mgmt database
- Problem Management techniques
|
|
Inputs
Scheduled Reviews
The Problem Manager regularly performs scheduled reviews of incident data and trending from the incident log to assess and identify potential problems.
IT Service Manager, Technical Staff Notification and Client Requests
Root Cause Analysis (RCA) requests escalated to Problem Management through Incident Management, Major Incident Review Mmeetings. The technical staff may determine potential problems through operational data, meetings, and reviews and bring them to the attention of the Problem Manager for further review.
Incident Log
Detailed file of all incidents reported and recorded.
Operational Data
Informational data captured regarding the operating environment, including data such as availability, capacity, and response times that can be utilized for statistical reporting and analysis.
Change Log
Detailed file of all changes that have occurred in the operational environment.
Identified Problems
Known problems that have been identified and logged by the technical support groups.
Controls
Service Level Agreements
Written, agreed upon with the client, and translated into service specifications by the IT staff responsible to fulfill the SLA. Service Level Agreements may also be agreed between support groups within IT to define parameters and procedures for hand-offs and assignments between groups.
Underpinning Contracts
Written agreements that specify service levels and technical specifications for vendor supported services and equipment. Technical specifications listed in the 3rd Party Agreements for vendor supported services and equipment.
Problem Management Guidelines
Operational guidelines, including process, procedures, and roles and responsibilities for the Problem Management process.
Communications
Includes any form of communication (e-mail, meetings, reports) that occurs internally within the IT support groups as well as communication with the client.
Technical Support Documents
Specific log files and documentation for individual technical support groups used to analyze and solve problems.
Mechanisms
Problem Management System
Tracking tool utilized to track, record, and report all Problem Management related activities.
Root Cause Analysis
Standardized techniques used by the organization to undercover and report the underlying causes of problems
Reports
Formalized reports that are distributed internally and to the client.
Knowledge Database
Documented results of RCA and workarounds and/or recommended solutions to be utilized for future problem analysis and investigation.
Problem Database
Known problems that have been identified and logged by the technical support groups.
Operational Database
Informational data captured regarding the operating environment, including data such as Availability, Capacity, and response times, which can be utilized for statistical reporting and analysis.
Outputs
Identified Problems
Problems deemed to require further investigation and documentation.
Problem Classification
Problems categorized based on severity levels and the problem classification scheme that determines priority and timing for review.
Request for Change
A proposed change to the environment or a configured item. A change may include moves and adds to individual items. A configuration item (CI) is an element in the production environment, such as hardware, software, network, or network software.
Updated Problem Log
Documented results of analysis and root cause analysis performed.
Recommendations
Recommended actions proposed for problem resolution. The recommended action may be a work around, or require a change to the operating environment. A recommendation may or may not be approved.
Updated Knowledge Database
Documented results of Root Cause Analysis (RCA) and work around and/or recommended solution to be utilized for future problem analysis and investigation.
Reporting
Formalized reports that are distributed internally and to the client.
Process Activities
 PM1 - Problem Mgmt. Level 2 Process - Proactive Problem Mgmt. Process
PM1 - Problem Mgmt. Level 2 Process - Proactive Problem Mgmt. Process
PM1.1 - Potential Problem Investigation
Proactive Problem Management activities are concerned with identifying and resolving Problems and Known errors before Incidents occur, thus minimizing the adverse impact on the service and business-related costs.
Problem prevention ranges from prevention of individual Problems, such as repeated difficulties with a particular feature of a system, through to strategic decisions. The latter may require major expenditure to implement, such as investment in a better network. Problem prevention also includes information being given to Customers that obviates the need to ask for assistance in the future. Analysis focuses on providing recommendations on improvements for the Problem solvers .
Problem analysis reports provide information for proactive measures to improve service quality. The objective is to identify 'unstable' components of an IT infrastructure and investigate the reasons for the instabilities.
PM1.2 - Problem Identification & Referral Potential
On completion of the resolution of every major Incident, Problem Management should complete a major Problem review. The appropriate people involved in the resolution should be called to the review to determine:
- What the solution is.
- What was done right.
- What was done wrong.
- What could be done better next time.
- What are the chances of the incident re-occurring.
- How permanent and robust was the solution implemented.
- How to prevent the Problem from happening again.
The result may well be the priority creation of a Problem Ticket.
PM2 - Problem Management - Problem & Error Control Process
Error control covers the processes involved in successful correction of Known errors. The objective is to change IT components to remove Known errors affecting the IT infrastructure and thus to prevent any recurrence of Incidents.
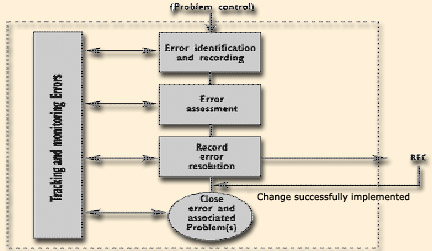
Error control spans both the live and development environments and directly interfaces with, and operates alongside Change Management processes. The Figure below shows the three phases of the error control process. The monitoring and tracking phase covers the entire Problem/error life-cycle.
PM 2.1 - Error Identification & Recording
An error is identified when a faulty component in the infrastructure (ie., CI that causes, or may be likely to cause, Incidents) is detected. A Known Error status is assigned when the root cause of a Problem is found and a Work-around has been identified.
There are two sources of Known Error data that feed the error control system. One is the Problem control subsystem in the live environment and the other its equivalent in the development environment. Known errors found during live operations are identified and recorded as described in Problem control activity investigation and diagnosis. In this case, the Problem record forms the basis of the Known Error record (involves a change of STATUS).
The second source of Known errors arises from development activity. For example, implementation of a new application or packaged Release is likely to include known, but unresolved, known errors from the development phase - the Defect List. This listing needs to be made available to the custodians of the live environment when an application or a Release package is implemented.
Many IT departments are involved in this sequence of events. The Problem Management system should provide a record of all resolution activity and provide monitoring and tracking facilities for support staff. It should also provide a complete audit trail navigable in either direction, from Incident to Problem to Known Error to Change request to Release or urgent Change implementation.
There are two sources of Known Error data that feed the error control system. One is the Problem control subsystem in the live environment> and the other its equivalent in the development environment. Known errors found during live operations are identified and recorded as described in Problem control activity investigation and diagnosis. In this case, the Problem record forms the basis of the Known Error record (involves a change of STATUS).
The second source of Known errors arises from development activity. For example, implementation of a new application or packaged Release is likely to include known, but unresolved, known errors from the development phase - the Defect List. This listing needs to be made available to the custodians of the live environment when an application or a Release package is implemented.
Many IT departments are involved in this sequence of events. The Problem Management system should provide a record of all resolution activity and provide monitoring and tracking facilities for support staff. It should also provide a complete audit trail navigable in either direction, from Incidents to Problem to Known Error to Change request to Release or urgent Change implementation.
PM2.2 - Error Assessment
Problem Management performs an initial assessment of the means of resolving the error, in collaboration with specialist staff. If necessary, they then complete an RFC according to Change Management procedures. The priority of the RFC is determined by the urgency and impact of the error on the business. The RFC identifier should be included in the Known Error record and vice versa in order to maintain a full audit trail, or the two records should be linked.
PM2.3 - Error resolution recording
The resolution process for each Known Error should be recorded in the Problem Management system. It is vital that data on the CIs, symptoms, and resolution or circumvention actions relating to all Known errors is held in the Known Error database. This data is then available for Incident matching, providing guidance during future investigations on resolving and circumventing Incidents, and for providing management information.
PM2.4 - Error closure
Following successful implementation of Changes to resolve known errors, the relevant Known Error record(s) is closed, together with any associated Incident or Problem records. A Post-Implementation Review (PIR) may be conducted on the closure to capture lessons learned. For Problems resulting from Incidents, this may involve nothing more than a telephone call to the user(s) to ensure that they are now content. For more serious Problems and Known errors, a formal review may be required.
PM2.5 - Problem/error resolution monitoring
Change Management is responsible for processing RFCs, whereas Problem Management is responsible for monitoring progress with regard to resolving Known errors. Throughout the resolution process, Problem Management should obtain regular reports from Change Management on progress in resolving Problems and known errors.
Problem Management should monitor the continuing impact of Problems and Known errors on User services. In the event that this impact becomes severe, Problem Management should escalate the Problem, perhaps referring to the Change Advisory Board to increase the priority of the RFC or to implement an urgent Change as appropriate.
The progress of Problem resolution should be monitored against SLAs. Typically, SLAs stipulate that there should not be more than a certain number of outstanding known errors per severity level during each measurement interval (generally a rolling four-week period). If the number of Problems or known errors at a severity level reaches a predefined threshold that looks likely to cause non-conformance to the SLAs, escalation should be invoked.
PM3 - Major Problem Review
On completion of the resolution of every major Incident, Problem Management should complete a Major Problem review. The appropriate people involved in the resolution should be called to the review to determine:
- what was done right
- what was done wrong
- what could be done better next time
- what are the chances of the incident re-occurring
- how permanent and robust was the solution implemented
- how to prevent the Problem from happening again.
The result may well be the priority creation of a Problem Ticket.
PM3.1 - Identify & Record Problem
Problem identification takes place when:
- matching the process to existing Problems and Known errors is not successful during the stage of Incident initial support and classification
- analysis of Incident data reveals recurrent Incidents
- analysis of Incident data reveals Incidents that are not yet matched to existing Problems or Known Errors
- analysis of the IT infrastructure indicates a Problem that could potentially lead to Incidents
- a major or significant Incident (serious and adverse impact on services to the Customer) occurs for which a structural solution has to be found.
It should be noted that some Problems may be identified by personnel outside the Problem Management team, e.g. by Capacity Management. Regardless, all Problems should be notified and recorded via the Problem Management process.
Problem records are recorded in a form very similar to Incident records and using the same Category, Type and Item (CTI) classification scheme. Problem records are linked to all associated Incident records and the solution and Workarounds of Incidents are recorded in the relevant Problem records for others to access should other related Incidents occur.
PM3.2 - Classify & Prioritize Problem
When a Problem is identified, the amount of effort required to detect and recover the failing CI(s) has to be determined. Therefore it is important to be aware of the impact of the Problem on existing service levels.
The steps involved in Problem classification are similar to the steps in classifying Incidents; they are to determine:
Problems are categorized into related groups or domains using the Category, Type and Item (CTI) designation.
Identification of a new Problem should be followed by an objective analysis of its impact (that is, its effect on the business). The relationships between components in the IT Infrastructure registered in the CMDB can be of great help when determining the impact of a Problem.
PM3.3 - Problem Investigation and Diagnosis
Problem Management's aim is diagnosis of the underlying cause of a current or potential fault in the infrastructure. Investigation activities should include available Workarounds for the Incidents related to the Problem, as registered in the Incident record database. Problem Management activities should include updating recommended Work-arounds in the Problem record, to support Incident control.
Diagnosis frequently reveals that the cause of a Problem is not an error in a registered CI (hardware, software item, documentation or procedure) but is procedural. Incorrect release of a version of a program is one example. These situations result in Problem closure with an appropriate categorization code. Problems of this type do not automatically achieve the formal status of Known Error. To ensure that these Problems are followed up and that action is taken to address them, consider creating a dummy CI record for the offending procedure and re-classifying the Problem as a Known Error, or raise an RFC referencing the need for a change to the documentation (which should under the control of Change Management, linked in the CMDB and stored as part of the DSL.
Diagnosis showing the cause to be a fault in a registered CI should automatically change the status of the Problem into a Known Error. At this point the error control system and procedures take over.
PM3.4 - Isolate the Problem
The problem manager begins the investigation process by analyzing the service disruption. A complete and accurate review of all documentation including the documentation recorded in Remedy Incident Ticket should be thoroughly conducted. This includes an analysis of:
- All of the CIs that are affected
- Incidents generated by customers
- Documentation provided by the service desk and incident management
- What customers are affected by the problem; is it an individual, a group, a site, or enterprise-wide
- Any steps taken by incident management to correct the incident
- Other relevant information including the history of service disruption
PM3.5 - Identify Similar Incidents by CI
Online service incidents are queried to determine all of the known incidents to the affected CI. These incidents are then grouped by incident type. For example, if the affected CI is a printer, this step may result in the identification of the following incident groups:
Use incident summaries to determine where to concentrate first efforts.
PM3.6 - Identify Similar Incidents by Customer
Online Service may be queried to determine the types of customers who report queue-related incidents. As an example, the results may indicate that one particular unit or group is responsible for the majority of these types of incidents.
PM3.7 - Isolate the Cause
Narrowing the scope of the problem to a specific group of customers and a specific type of incident helps reduce the time needed to identify the root cause and resolve the problem. In this example, problem management narrows the scope to finance employees experiencing queue-related issues with a printer.
The next step is to investigate the applications that the finance employees are attempting to print to the CI. In this example, the results are as follows:
- 95% have difficulty printing from the general ledger application
- 5% are experiencing problems from other applications
The real problem is now identified, but the underlying factors remain undetermined. Problem Management should now attempt to determine the root cause of the problem. In this case, problem management might decide to query Trouble Tickets for Solutions to the problem. The component most frequently manipulated to affect resolution is most likely the root cause. In this example, the query might yield the following results:
- 87% of resolution was handled by restarting the printer
- 10% of resolution was handled by eliminating or restarting print jobs in queue
- 3% of resolution was handled by other means
Although the problem was originally thought to be queue-related, further investigation revealed that the root cause was not queue related but actually hardware specific. In this example, the printer would be recorded as the source of the problem. If the problem can be resolved immediately, with no further action required to permanently correct the issue, then the status of the problem record (PR) in the Remedy Problem Management module is changed to resolved. If the problem requires more analysis or the submission of an RFC to be corrected, the status of the PR in the Problem Management module would be changed to a known error and the error control activity would be started to resolve it.
PM3.8 - Resolve Problem
Where the root cause of a problem identifies a cause unrelated to a Configuration Item (CI) the problem can be resolved without recourse to Change Management procedures. For example, where the root cause is training or communications for which existing documented procedures (since these should be CIs) are not at issue (eg., failure to follow procedures, lack of awareness of them, etc) then the problem can be addressed without the need for an RFC.
Terms
| Term | Definition
|
| Availability | Ability of a component or service to perform its required function at a stated instant or over a stated period of time. It is usually expressed as the availability ratio, i.e. the proportion of time that the service is actually available for use by the Customers within the agreed service hours.
|
| Category, Type and Item (CTI) | Method for Classification of a group of Change documents according to three-fold hierarchical coding structure used by many organizations.
|
| Client | People and/or groups who are the targets of service. To be distinguished from User - the consumer of the target (the degree to which User and Client are the same represents a measure of correct targeting) and the Customer - who pays for the service.
|
| Causal Factors | Those contributors (human known errors and component failures) that, if eliminated, would have either prevented the occurrence of an incident or reduced its severity.
|
| Classification | Process of formally identifying Incidents, Problems and Known errors by origin, symptoms and cause.
|
| Change Management | Process of controlling Changes to the infrastructure or any aspect of services, in a controlled manner, enabling approved Changes with minimum disruption.
|
| Configuration Item (CI) | Component of an infrastructure - or an item, such as a Request for Change, associated with an infrastructure - that is (or is to be) under the control of Configuration Management.CIs may vary widely in complexity, size and type, from an entire system (including all hardware, software and documentation) to a single module or a minor hardware component.
|
Configuration Management
Database (CMDB) | A database that contains all relevant details of each CI and details of the important relationships between CIs.
|
| Core Business Process | A process that relies on the unique knowledge and skills of the owner and that contributes to the owner’s competitive advantage.
|
| Critical Success Factor (CSF) | Critical Success Factors - the most important issues or actions for management to achieve control over and within its' IT processes.
|
| Customer | Payer of a service; usually theCustomer management has responsibility for the cost of the service, either directly through charging or indirectly in terms of demonstrable business need.
|
| Environment | A collection of hardware, software, network and procedures that work together to provide a discrete type of computer service. There may be one or more environments on a physical platform e.g. test, production. An environment has unique features and characteristics that dictate how they are administered in similar, yet diverse, manners.
|
| Error Control | The processes involved in progressing Known errors until they are eliminated by the successful implementation of a Change under the control of the Change Management process.
|
| Impact | Measure of the business criticality of an problem often equal to the extent to which Incidents lead to distortion of agreed or expected service levels.
|
| Incident | Any event that is not part of the standard operation of a service and that causes, or may cause, an interruption to, or a reduction in, the quality of that service.
|
| Known Error | An Incident or Problem for which the root cause is known and for which a temporary Work-around or a permanent alternative has been identified. If a business case exists, an RFC will be raised, but, in any event, it remains a known error unless it is permanently fixed by a Change.
|
| Mean Time to Repair (MTTR) | The elapsed time to restore service measured from either the time of the failure or the time the failure was reported to the time the service was restored to the Users satisfaction.
|
| Priority | Sequence in which an Incident or Problem needs to be resolved, based on impact and urgency.
|
| Problem Control | Process which is concerned with handling Problems in an efficient and effective way with the aim of identifying the root cause of incident(s) and to provide the Service Desk with information and advice on Work-arounds when available.
|
| Process | A connected series of actions, activities, Changes etc. performed by agents with the intent of satisfying a purpose or achieving a goal.
|
| Process Control | The process of planning and regulating, with the objective of performing a process in an effective and efficient way.
|
| Release | A collection of new and/or changed CIs which are tested and introduced into the live environment together.
|
| Request for Change (RFC) | Form, or screen, used to record details of a request for a Change to any CI within an infrastructure or to procedures and items associated with the infrastructure.
|
| Resolution | Action that will resolve an Incident. This may be a Work-around.
|
| Role | A set of responsibilities, activities and authorisations.
|
| Service Level Agreement | A written agreement between a service provider and Customer(s) that documents agreed services and the levels at which they are provided at various costs.
|
| Service Level Management | Disciplined, proactive methodology and procedures used to ensure that adequate levels of service are delivered to supported IT users in accordance with business priorities and at acceptable costs.
|
| Service Request | Every Incident not being a failure in the IT Infrastructure.
|
| System | An integrated composite that consists of one or more of the processes, hardware, software, facilities and people, that provides a capability to satisfy a stated need or objective.
|
| Urgency | Measure of the business criticality of an Incident or Problem based on the impact and on the business needs of the Customer.
|
| Version | An identified instance of a Configuration Item within a product breakdown structure or configuration structure for the purpose of tracking and auditing change history. Also used for software Configuration Items to define a specific identification released in development for drafting, review or modification, test or production.
|
| Work-around | Method of avoiding an Incident or Problem, either from a temporary fix or from a technique that means the Customer is not reliant on a particular aspect of a service that is known to be a problem.
|
Problem Management Techniques
There are three generally accepted tools for structuring the completion of these tasks...
Kepner-Tregoe Problem Analysis
Kepner-Tregoe is the most widely accepted methodology for structuring a Problem in a way which facilitates analysis.
A problem is defined as �a situation where there is deviation from expected results, and
the causes for the deviation are not known�. What we normally notice is an effect, something that happens and can be observed. This effect had a cause, that normally is invisible. It is this cause that at some point in time produced a change, and so caused the effect, the deviation from from expected results.
To correct the deviation we need to find the most probable cause.
First we have to define as well as possible what is the standard functioning and what is the present functioning. Kepner-Tregoe advocates filling in a spreadsheet something like the following:
| State the problem: |
|
Data for checking a possible cause |
Data for stimulating thought
about a possible cause |
|
What is wrong
in the way the object
looks, sounds, feels, smells
|
What is NOT wrong
this time, even though
it is related, or was
wrong, at other times |
Peculiarities
and diferences
about the "wrong"
and "NOT wrong" columns
|
Changes
What, and at what
time, related with
the "wrong" column
|
What is the object,
person, process
where you observe the defect
or problem.
|
-
-
-
-
|
(in what object do you NOT observe the defect)
-
-
-
|
-
-
-
-
|
-
-
-
-
|
Where in the object
are the defects.
Where do you observe
the defective objects |
-
-
-
-
|
(where do you NOT observe the defect)
-
-
-
|
-
-
-
-
|
-
-
-
-
|
When did the objects
or the defects at the
objects first appear.
Hour, circumstance? |
-
-
-
-
|
(when did you NOT observe them)
-
-
-
|
-
-
-
-
|
-
-
-
-
|
How many or what
percentage of
defective objects, or
defects per object
do you observe.
Increasing? Size?
|
-
-
-
-
-
-
|
-
-
-
-
-
-
|
-
-
-
-
-
-
|
-
-
-
-
-
-
|
In the first column we fill in, with a few words, what precisely we can observe. A good definition of the problem is of great help in solving it.
The second column is of great importance. Here we look for contrast. If there are several machines and one has the problem, here we write down what is not wrong with the other machines, even though they could have the same problem. Or if it is just one machine, we try to contrast its problem with its prior functioning: what do we observe now but did not observe before. Or we could ask ourselves what was wrong sometime in the past, but is not the case now. Or what could reasonably go wrong, but is not the case now. Also we establish limits. The problem could be bigger or smaller, we state what we could have observed, but did not. The information in this column permits us to look for differences of all kinds.
In the third column we fill in peculiarities and differences, when looking at the first two columns.
We write down what distinguishes that what we have written in the first column from that written in the second column (But we do not mention causes or effects).
In the fourth column we write down the change. When did each of the items, written down in the first column, change realted to the peculiarity noted in the third column. Under what circumstances did it change.
When we have filled our the form completely we state all possible changes that could correspond with the data on this spreadsheet. These changes have to comply with the "wrong" column, the "NOT wrong" column, the "peculiarities" column and the "change" column. If a "change" does not correspond to these items, it is not one of the possible causes.
It should now be possible to state the most probable cause. The cause is either the change itself or the change that permitted the cause to act.
Now ask the question: "With this most probable cause, shouldn't we see other changes caused by it?
Look for these other changes. If they are observable, then our most probable cause is right.
Ishikawa (Cause and Effect) Diagrams
The basic concept in the Cause-and-Effect diagram is that the name of a basic problem of interest is entered at the right of the diagram at the end of the main "bone".

The main possible causes of the problem (the effect) are drawn as bones off of the main backbone. The"Four-M" categories are typically used as a starting point: "Materials", "Machines", "Manpower", and "Methods". Different names can be chosen to suit the problem at hand, or these general categories can be revised. The key is to have three to six main categories that encompass all possible influences. Brainstorming is typically done to add possible causes to the main "bones" and more specific causes to the "bones" on the main "bones". This subdivision into ever increasing specificity continues as long as the problem areas can be further subdivided. The practical maximum depth of this tree is usually about four or five levels. When the fishbone is complete, one has a rather complete picture of all the possibilities about what could be the root cause for the designated problem.
The Cause-and-Effect diagram can be used by individuals or teams; probably most effectively by a group. A typical utilization is the drawing of a diagram on a blackboard by a team leader who first presents the main problem and asks for assistance from the group to determine the main causes which are subsequently drawn on the board as the main bones of the diagram. The team assists by making suggestions and, eventually, the entire cause and effect diagram is filled out. Once the entire fishbone is complete, team discussion takes place to decide what are the most likely root causes of the problem. These causes are circled to indicate items that should be acted upon, and the use of the tool is complete.
The Ishikawa diagram, like most quality tools, is a visualization and knowledge organization tool. Simply collecting the ideas of a group in a systematic way facilitates the understanding and ultimate diagnosis of the problem.
Root Cause Analysis
Root Cause Analysis is itself a formal methodology composed of four primary steps...
- Data Collection and Preservation - The first step is to gather data. This is where the organization reaps some of the benefits of quality assurances activities in Incident Ticket reporting. Without complete information and an understanding of the incident, the causal factors and root causes associated with the incident cannot be adequately identified. The majority of time spent analyzing an incident will be spent in gathering data.
- Causal Factor (CF) Charting - CF Charting provides a way for investigators to organize and analyze the informaiton gathered during the investigation and to identify gaps and deficiencies in knowledge as the investigation progresses. The CF chart is simply a sequence diagram that describes the events leading up to and following an incident, as well as the conditions surrounding the incident. The final step in CF charting involves identifying the major contributors to the occurrence (i.e. causal factors).
- Root Cause Identification - This step involves the use of a decision diagram called a Root Cause Map to identify the underlying reasons for each causal factor identified during CF charting. The identification of root causes helps the investigator of a specific incident determine the reasons why the incident occurred so that the problems surrounding its' occurrence can be fixed. In addition, trending of the root causes of occurrences over a period of time can provide valuable insight concerning specific areas for improvement.
- Recommendation Generation and Implementation - The last step is the generation of recommendations. This may be specific, achievable suggestions for preventing the recurrence of the incident(s) or a Request for Change to remove the cause of the incident(s).
Root Cause Determined
When the root cause of a problem is identified, the problem is reclassified as a known error. Investigation into the resolution of the known error continues until a solution is identified. At the time it is corrected, a request for change (RFC) is submitted to change management in order to implement the correction. In most cases, a work-around (a temporary solution) is developed by incident management to restore customer service as quickly as possible. Problem management typically reviews work-arounds that are developed by incident management to ensure that the best temporary solution is selected. Sometimes incident management participates in the actual development of the work-around.
The problem management process seeks to permanently correct problems so that they do not reoccur in the IT environment. During the problem management process a few solutions are possible:
- The problem is identified and eliminated. This indicates that the source of the problem was an isolated one. The cause of the problem was not infrastructure related and was resolved and is not expected to recur.
- A work-around is created. This indicates that the source of the problem has the potential to affect other customers and is not expected to be isolated to a particular customer. The problem is related to an infrastructure CI but does not necessarily represent a significant infrastructure failure. Rather, it is a glitch in operations, or a minor infrastructure event. The result is a tolerance for the problem within the organization and a method for the service desk to get customers back into productive service in the event of a recurrence. Although a work-around is a solution, it is temporary. Problem management should continue to search for the root cause and eliminate it from the infrastructure. A work-around may be created at any point in the problem management process (that is, for problems and known errors). Typically, work-arounds are developed by incident management and are reviewed by problem management to ensure that the resolution selected is the best solution available.
- The problem is designated as a known error. This indicates that the source of the problem has been identified. When the problem is identified, the error control process begins and a solution is identified. The solution typically results in the submission of an RFC to change management to correct the problem.
